- Topic1/3
18k Popularity
34k Popularity
19k Popularity
6k Popularity
173k Popularity
- Pin
- Hey fam—did you join yesterday’s [Show Your Alpha Points] event? Still not sure how to post your screenshot? No worries, here’s a super easy guide to help you win your share of the $200 mystery box prize!
📸 posting guide:
1️⃣ Open app and tap your [Avatar] on the homepage
2️⃣ Go to [Alpha Points] in the sidebar
3️⃣ You’ll see your latest points and airdrop status on this page!
👇 Step-by-step images attached—save it for later so you can post anytime!
🎁 Post your screenshot now with #ShowMyAlphaPoints# for a chance to win a share of $200 in prizes!
⚡ Airdrop reminder: Gate Alpha ES airdrop is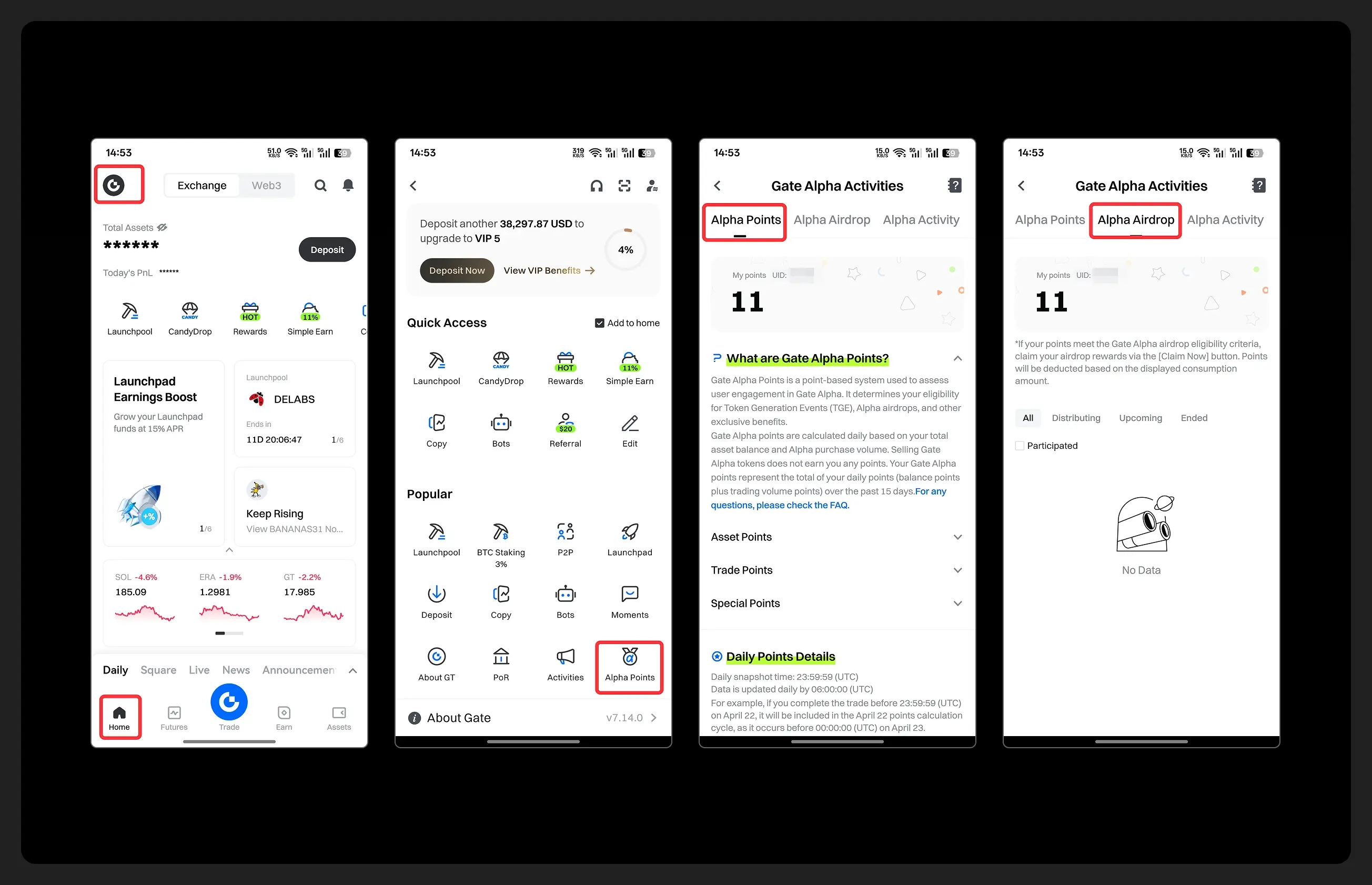
- Gate Futures Trading Incentive Program is Live! Zero Barries to Share 50,000 ERA
Start trading and earn rewards — the more you trade, the more you earn!
New users enjoy a 20% bonus!
Join now:https://www.gate.com/campaigns/1692?pid=X&ch=NGhnNGTf
Event details: https://www.gate.com/announcements/article/46429
- Hey Square fam! How many Alpha points have you racked up lately?
Did you get your airdrop? We’ve also got extra perks for you on Gate Square!
🎁 Show off your Alpha points gains, and you’ll get a shot at a $200U Mystery Box reward!
🥇 1 user with the highest points screenshot → $100U Mystery Box
✨ Top 5 sharers with quality posts → $20U Mystery Box each
📍【How to Join】
1️⃣ Make a post with the hashtag #ShowMyAlphaPoints#
2️⃣ Share a screenshot of your Alpha points, plus a one-liner: “I earned ____ with Gate Alpha. So worth it!”
👉 Bonus: Share your tips for earning points, redemption experienc
- 🎉 The #CandyDrop Futures Challenge is live — join now to share a 6 BTC prize pool!
📢 Post your futures trading experience on Gate Square with the event hashtag — $25 × 20 rewards are waiting!
🎁 $500 in futures trial vouchers up for grabs — 20 standout posts will win!
📅 Event Period: August 1, 2025, 15:00 – August 15, 2025, 19:00 (UTC+8)
👉 Event Link: https://www.gate.com/candy-drop/detail/BTC-98
Dare to trade. Dare to win.
How do data availability solutions work and how do they differ?
**Written by: **zer0kn0wledge.era
Compiled by: Kate, Marsbit
Note: This article is from @expctchaos Twitter, which is a researcher of @ChaosDAO. The content of the original tweet is organized by MarsBit as follows:
0/ Data Availability (DA) is the main scaling bottleneck
Luckily @CelestiaOrg, @AvailProject and @eigenlayer will change the DA game and enable new levels of scalability
But how does it work and how is #EigenDA different from DA 15 like #Celestia and #Avail?
1/ If you are not familiar with data availability issues, please check out my post below where I describe the data availability situation in detail 👇
2/ In general, there are two main types of data processing solutions
3/ And "pure validity verification" means that data processing can be off-chain without guarantees, because off-chain data service providers can go offline at any time...
4/ …#StarkEx, #zkPorter and #Arbitrum Nova are examples of verification scenarios that rely on DAC, a group of well-known third parties to guarantee data availability
5/ On the other hand, #EigenDA, @CelestiaOrg and @AvailProject are what we could call a universal DA solution
However, there are some differences between EigenDA and the other two solutions
6/ If you want to know how @CelestiaOrg works, check out the link below
7/ I've covered @AvailProject in the past too, so to learn more check it out here
8/ If you need a refresher on @eigenlayer, check out the thread below 👇
9/ So in today's post we want to focus on the comparison between @eigenlayer's #EigenDA and DA L1 chains like @CelestiaOrg or @AvailProject
10/ Let's assume a rollup based on Ethereum and using Celestia for DA (aka Celestium)
So L2 contracts on Ethereum verify proof of validity or proof of fraud as usual, and DA is provided by Celestia
11/ On @CelestiaOrg and @AvailProject, there are no smart contracts or computations, only data is guaranteed to be available
12/ But let's take a closer look
On @CelestiaOrg, tx data is published to Celestia by L2 sorter, Celestia verifier signs Merkle root of DA proof, then sent to DA bridge contract on Ethereum for verification and storage
13/ Compared to storing DA on-chain, this greatly reduces the cost of having a strong DA guarantee, while also providing security guarantees from Celestia (rather than a centralized DAC)
14/ Cost reduction will change the rules of the game in the entire rollup field, because the cost of calldata generated by publishing data to Ethereum L1 accounts for 80-90% of the rollup cost
For more information on calldata cost, check out the post below 👇
15/ But what the hell happened on #Celestia?
Data blobs posted to @CelestiaOrg (essentially as raw data) are propagated through the P2P network and consensus about the data blob is reached using Tendermint consensus
16/ Every #Celestia full node must download the entire data blob. This is different for light nodes which can use Data Availability Sampling (DAS) to ensure data availability
17/ For more information about DAS and light nodes, please check the post below
18/ We will also come back to DAS later in this thread, but for now the focus is on full nodes
So back to @CelestiaOrg, which continues to behave in an L1 fashion, relying on broadcasting and consensus on data blobs
19/ Therefore, it places high demands on the full nodes of the network (128 MB/s download and 12.5 MB/s upload).
Still, @CelestiaOrg was aiming for moderate throughput (1.4 MB/s) at the start, which seems low given the full node requirements
20/ However, the network can scale throughput by adding light nodes. The more data sampling light nodes, the larger the block size can be under the condition of ensuring security and decentralization
21/ On the other hand, @eigenlayer has a different architecture, no consensus of its own, and no peer-to-peer network
So how does this work?
First, the EigenDA node must reallocate $ETH in the @eigenlayer contract. Therefore, #EigenDA nodes are a subset of Ethereum validators
22/ After receiving the data blob, a DA buyer (such as a rollup, also known as a disperser) then encodes it with an erasure code and generates a KZG commitment…
23/…where the proof size depends on the redundancy ratio of the erasure code and publishes KZG’s commitment to the #EigenDA smart contract
24/ Encoded KZG commitment distributed by disperser to #EigenDA nodes
After receiving the KZG commitment, these nodes compare it with the KZG commitment of the EigenDA smart contract and sign the proof after confirmation
25/ After that, the disperser collects these signatures one by one, generates an aggregated signature, and publishes it to the #EigenDA smart contract, and the smart contract verifies the signature
26/ But if the #EigenDA node simply signs a proof claiming it stored the encoded data blob in this workflow, and the EigenDA smart contract only verifies the correctness of the aggregated signature, how can we be sure that the EigenDA node really stored data?
27/ #EigenDA uses a escrow proof method to achieve this
But let's take a step back and look at this scene where it becomes important
28/ Let's assume some lazy validators are not doing the tasks assigned to them (e.g. making sure data is available)
Instead, they pretend they've done the work and sign off on the end result (falsely reporting data availability when it's not available).
29/ Conceptually, proof of custody is like proof of fraud:
Anyone can submit a proof (validator lazy) to the #EigenDA smart contract which will be verified by the smart contract
29/ Lazy validator is slashed if validation is successful (because it is an objectively attributable error)
30/ What about consensus?
@CelestiaOrg uses Tendermint as its consensus protocol, which has single-slot finality. That is, once a block passes #Celestia consensus, it's done. This means finality is basically as fast as block time (15 seconds).
31/ @AvailProject uses protocol composition to achieve finality. BABE is a block production mechanism with probabilistic finality, and GRANDPA is a final gadget. While GRANDPA can complete blocks in one slot, it can also complete multiple blocks in a round
32/ Since @eigenlayer is a set of smart contracts on Ethereum, it also inherits the same finalization time as Ethereum (12 - 15 minutes) for data that needs to be forwarded to the rollup contract to prove data availability
33/ However, if the rollup uses @eigenlayer at all, it could be done faster, depending on the consensus mechanism used etc.
Additionally, middleware secured by @eigenlayer's restaking validators focused on providing fast settlements, such as EigenSettle can provide strong economic security guarantees allowing finality pre-confirmation. However, hard finality guarantees still come from Ethereum L1
34/ Time to Revisit Data Availability Sampling Concepts
In most blockchains, nodes need to download all transaction data to verify the availability of the data. The problem this creates is that when the block size increases, the number of data nodes that need to be verified also increases
35/ Data Availability Sampling (DAS) is a technique that allows light nodes to verify data availability by downloading only a small portion of block data
36/ This provides security to light nodes so that they can validate invalid blocks (DA and consensus only) and allows the blockchain to scale data availability without increasing node requirements
37/ DAS requires at least one honest full node and a sufficient number of light clients
38/ But how to ensure the security of light nodes?
Traditional light clients have weaker security assumptions compared to full nodes since they only validate block headers
Therefore, light clients cannot detect whether an invalid block was produced by a dishonest majority of block producers
39/ Light nodes with data availability sampling are upgraded in security, because if DA layer only does consensus and data availability, they can verify whether invalid blocks are produced
40/ Both @CelestiaOrg and @AvailProject will have data availability sampling so their light nodes will have trust-minimized security.
41/ This is different from Ethereum and @eigenlayer
Ethereum with #EIP4844 has no data availability sampling, so its light clients will not have trust-minimized security
42/ Since Ethereum also has its smart contract environment, light clients also need to verify execution (via fraud or proof of validity), rather than relying on most assumptions of honesty
43/ @eigenlayer (unless there is a DAS) light client, if supported, will rely on an honest majority of restaking nodes
Therefore, the security of #EigenDA is mainly based on the Ethereum validator set, inheriting the Ethereum slashing primitive and ensuring the economic security of DA
44/ So more stakeholder participation in #EigenDA means greater security. Reducing node requirements also contributes to better decentralization
45/ Erasure coding is an important mechanism that enables data availability sampling. Erasure coding expands blocks by making additional copies of the data. Additional data creates redundancy, providing stronger security guarantees for the sampling process
46/ However, nodes may attempt to encode data incorrectly in order to disrupt the network. To defend against this attack, nodes need a way to verify that the encoding is correct - this is where proofs come in.
47/ Ethereum, @eigenlayer and @AvailProject all use a proof of validity scheme to ensure blocks are correctly encoded. The idea is similar to the validity proofs used by zk rollup. @eigenlayer has discussed this earlier in this thread
48/ Every time a block is generated, the verifier must make a commitment to the data verified by the node using KZG proof to prove that the block is correctly encoded
49/ Although generating commitments for KZG proofs requires more computational overhead for block producers, when the blocks are small, generating commitments does not bring much overhead. However, this changed...
50/… as the blocks get bigger, the burden of the commitment of the KZG proof is much higher
Therefore, the type of node responsible for generating these commitments may have higher hardware requirements
51/ On the other hand, @CelestiaOrg implements fraud proofs for erasure coding. Therefore, #Celestia nodes do not need to check that blocks are correctly encoded. they default it to be correct
52/ The benefit is that block producers do not need to do the expensive work of generating erasure coded commitments
But there is a tradeoff, because light nodes have to wait a short time before assuming a block is correctly encoded, and completing it in their view
53/ The main difference between fraud-proof and validity-proof encoding schemes is the trade-off between node overhead for generating commitments and latency for light nodes
54/ This table nicely summarizes the comparison